



Soul开源SoulX-Singer,零样本歌声合成进入工业应用阶段
编辑: 肖霞来源: 经济晚报2026-03-06 10:14:17

编辑: 肖霞来源: 经济晚报2026-03-06 10:14:17
近日,Soul App AI团队(SoulAILab)联合吉利汽车研究院人工智能中心、天津大学及西北工业大学,正式开源歌声合成模型SoulX-Singer。该模型基于超过42000小时训练数据,支持普通话、英语、粤语零样本歌声合成,在稳定性与可控性方面达到开源领域领先水平。
歌唱语音合成(SVS)技术旨在根据歌词与乐谱生成人声演唱,相比普通语音合成,其对音高、旋律和演唱风格的控制要求更为精细。长期以来,开源社区缺乏真正稳定可用的零样本SVS模型,制约了该技术在虚拟歌手、音乐创作等场景的应用落地。SoulX-Singer的发布,正是为解决这一行业痛点而生。
在技术架构上,SoulX-Singer采用FlowMatching生成建模范式,将歌声合成建模为音频补全任务。针对歌词、旋律、发声三者强耦合的特点,模型引入音符级别对齐机制,精确建模每个音符的起止时间、音高和持续时长,既保证乐谱还原的准确性,又支持灵活的音乐编辑与重编曲。
数据规模是零样本能力的基石。SoulX-Singer依托42000余小时高质量歌声数据训练,覆盖多语言、多音色及多种演唱风格。这使得模型面对未见过的新歌手时,仍能输出稳定自然的合成效果,实现从技术演示到工业可用的关键跨越。
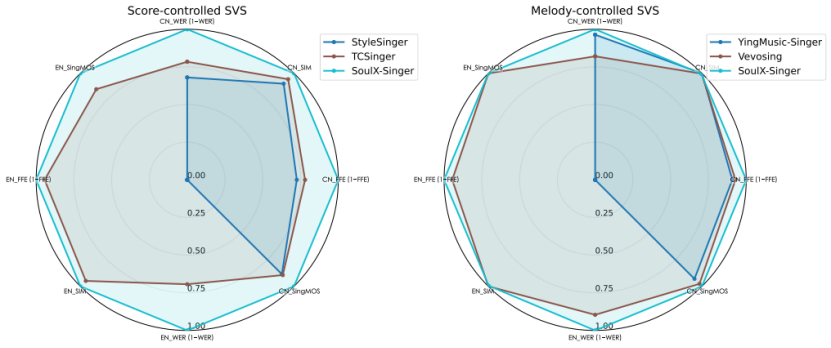
在控制方式上,SoulX-Singer提供Music Score与Melody双模态驱动。MusicScore模式基于MIDI乐谱生成歌声,支持音符级时长节奏控制,适用于原创音乐与歌词编辑;Melody模式则以现有旋律为参考,复刻演唱技巧,适用于翻唱与风格迁移。两种模式覆盖从零创作到二次改编的完整workflow。
语言支持方面,SoulX-Singer目前涵盖普通话、英语、粤语三种语言,且在各语种下均保持一致的合成质量,为多语言虚拟歌手打造和跨文化音乐创作提供技术支撑。
评测结果显示,SoulX-Singer在GMO-SVS和SoulX-Singer-Eval数据集上,于语义清晰度、歌手相似度、基频一致性等维度均优于现有开源方案,主观听感评测同样表现领先。其中SoulX-Singer-Eval数据集专门面向严格零样本场景构建,确保测试歌手未出现在训练集中。
客观表现
此次开源延续了SoulAI团队的技术开放路线。此前该团队已陆续开源SoulX-Podcast播客合成模型与SoulX-FlashTalk实时数字人模型,形成覆盖语音、歌声、数字人、视频的多模态生成技术矩阵。
目前,SoulX-Singer技术报告、源代码及模型权重已全面开放,全球开发者可通过GitHub、HuggingFace等平台获取。研发团队表示将持续优化模型,拓展更多语言与风格支持,推动AI歌声合成技术在UGC音乐创作等领域的广泛应用。
SoulX-Singer的发布,为专业音乐人提供了高效创作辅助,也为普通用户打开了参与音乐创作的新窗口,标志着AI音乐生成技术向实用化、普惠化迈出重要一步。
免责声明:本文为企业宣传商业资讯,仅供用户参考,如用户将之作为消费行为参考,经济晚报敬告用户需审慎决定。